
小鹏汽车联合北大发布论文入选国际AI顶会AAAI 2026,树立车端大模型高效部署上车新标杆
论文贡献
- 我们提出了FastDriveVLA,一种新颖的基于重建的Token剪枝框架,它不同于现有的基于注意力的和基于相似性的剪枝方法。
- 我们设计了ReconPruner,这是一种通过MAE风格像素重建训练的、即插即用的剪枝器,并引入了一种新颖的对抗性前景-背景重建策略,以增强其识别有价值Token的能力。
- 我们构建了nuScenes-FG数据集,包含针对自动驾驶场景的前景分割标注,总计包含24.1万个图像-掩码对。
- 我们的方法专为端到端自动驾驶VLA模型定制,并在nuScenes开环规划基准测试中实现了SOTA性能(即当前最优的效果)。
【12月28日】近日,AAAI 2026公布了论文录用结果,该会议是人工智能领域的国际顶级会议之一。据悉,AAAI 2026共收到23,680份论文投稿,其中4,167篇论文被录用,录用率仅为17.6%。由小鹏汽车和北京大学计算机学院多媒体信息处理全国重点实验室联合完成的论文《FastDriveVLA: Efficient End-to-End Driving via Plug-and-Play Reconstruction-based Token Pruning》成功入选。这篇论文最大的贡献在于,提出了一种专门为端到端自动驾驶VLA模型定制的、高效的视觉Token剪枝框架——FastDriveVLA。
随着AI大模型技术的加速演进,VLA(视觉-语言-动作)模型由于在复杂场景理解与动作推理方面展示出巨大潜力,正在被广泛地应用于端到端自动驾驶系统中。VLA模型在处理视觉信息时,会将图像编码为海量视觉Token(词元)。视觉Token是VLA模型“看懂世界”,并“做出决策”的基石,其质量、数量与选择策略直接决定模型的性能、效率与可信度。然而,直接转换的处理方式会导致车端计算负荷变大,同时还会影响模型的推理效率和决策执行。
此前,视觉Token剪枝已被证实了是加速VLA模型推理的可行方法之一。但传统的视觉Token剪枝方法或依赖文本-视觉注意力关联,或基于Token相似度去重,在驾驶场景中均存在明显局限。为了解决这一问题,小鹏汽车联合北大共同提出了FastDriveVLA——一种专门为自动驾驶设计的、基于重建视觉Token剪枝框架。该框架的提出受到了人类驾驶员在驾驶时会专注于相关前景信息(如行人、道路、车辆、交通标志、交通信号灯、交通障碍物)的启发,引入了一种新颖的对抗性前景-背景重建策略,以增强VLA模型识别有价值Token的能力,从而教会AI“像人一样开车”,自动过滤无关紧要的视觉信息,只关注有用的核心信息。
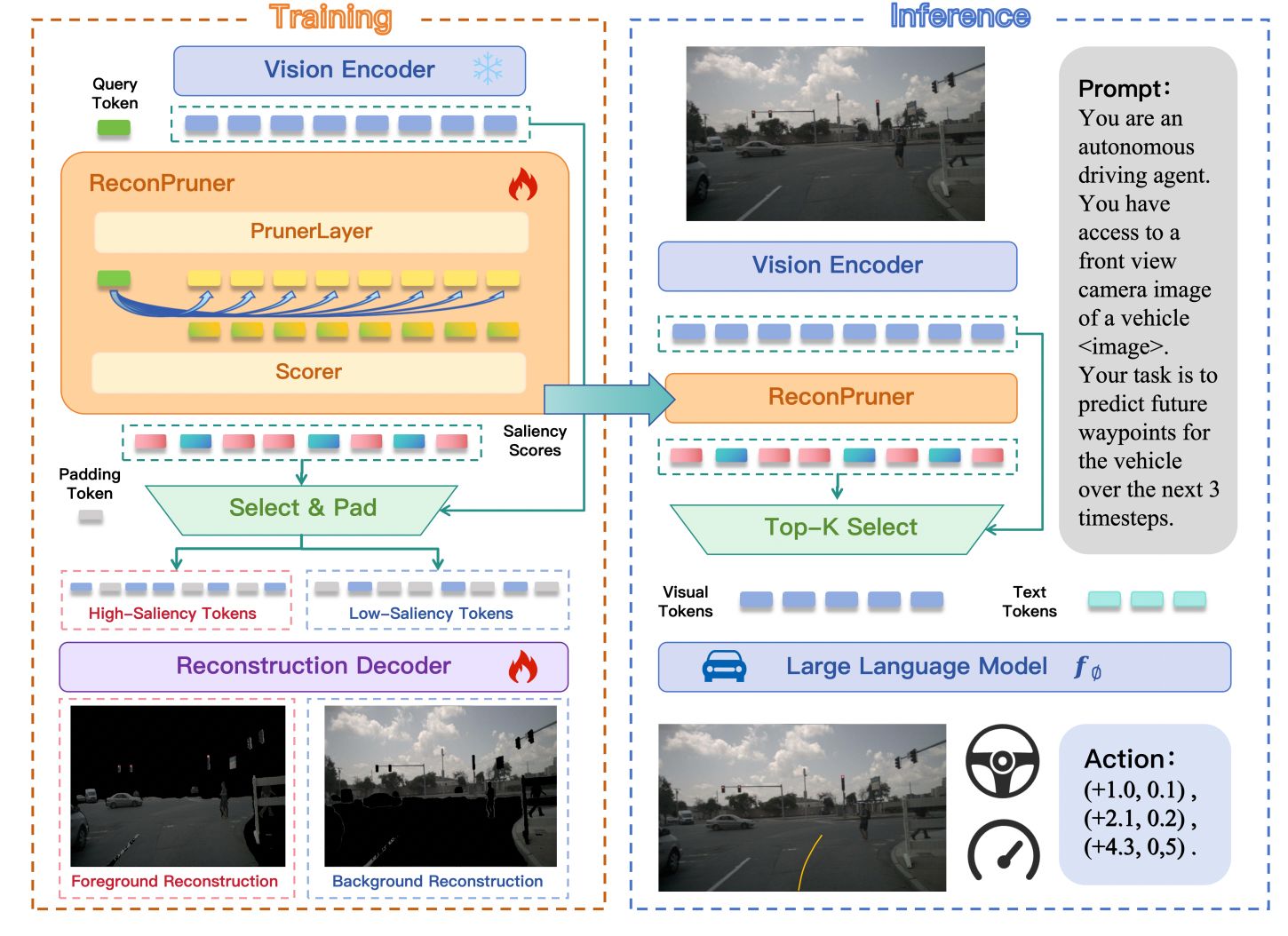
图1:FastDriveVLA 框架
在训练阶段,论文中提出了一种新颖的“前景-背景对抗重建”策略,以增强 ReconPruner 对前景视觉 Token 的感知能力;在推理阶段,ReconPruner可直接嵌入自动驾驶VLA模型,用于 Token 剪枝。
FastDriveVLA包含一个即插即用的视觉Token剪枝器ReconPruner。在车端模型的推理阶段, ReconPruner可直接嵌入自动驾驶VLA模型用于视觉Token的剪枝,即插即用,无需重新训练整个模型。为了辅助该剪枝器的训练,还专门构建了包含来自6个摄像头视角的24.1万个图像-掩码对的nuScenes-FG数据集。这一大规模的自动驾驶前景分割标注数据集,可广泛用于未来自动驾驶的研究。

图2:nuScenes-FG。该数据集为 nuScenes 场景提供了 24.1 万个前景分割标注。
这种“去繁从简”只关注核心驾驶信息的思路,让FastDriveVLA取得了惊艳的效果。最终,nuScenes自动驾驶数据集上的测试显示,采用这一剪枝框架,在不同剪枝率下均取得当前最优即SOTA效果:
剪枝比例达25%视觉Token时,驾驶性能几乎不下降,其L2轨迹误差与碰撞率指标甚至超越未剪枝的基准模型;
剪枝比例达50%Token时,在所有指标上表现更平衡;
与此同时,VLA模型的推理效率得到了显著提升。当视觉Token数量从 3249减少到 812时,FastDriveVLA 实现了近7.5倍的计算量(FLOPs)减少。在 CUDA (指从GPU启动一个计算任务到真正拿到该任务的计算结果之间所经历的时间)延迟方面,FastDriveVLA 将预填充时间(prefill)与解码时间(decode)分别减少了 3.7倍与1.3倍。
小鹏汽车联合北大提出的FastDriveVLA,建立了自动驾驶VLA模型的高效视觉Token剪枝的新范式,同时树立了车端大模型高效部署上车的新标杆。
此次论文入选AAAI 2026,是小鹏汽车今年第二次参与人工智能领域的国际顶级会议。早在今年6月,小鹏汽车曾作为CVPR WAD唯一邀请演讲中国车企,分享自动驾驶基座模型研发进展。在今年11月的科技日上,小鹏汽车正式推出第二代VLA,创新性地去掉了“语言转译”环节,首次实现从视觉信号到动作指令的端到端直接生成,颠覆了行业传统的「V-L-A」架构,探索全新物理AI模型范式。这些成果都为全球自动驾驶的研究和实践注入了全新的动力。
这一系列成果也彰显了小鹏汽车从模型架构设计、模型训练到模型蒸馏、部署上车的全栈自研能力。未来,小鹏汽车将继续以L4为目标,在AI大模型领域加大投入,加速物理AI大模型上车,让更安全、高效、舒适的智驾体验惠及全球用户。
本文由方向对了资讯网发布,不代表方向对了资讯网立场,转载联系作者并注明出处:https://www.zhenyes.com/auto/6477.html
