
英特尔Panther Lake处理器深度解析:18A制程加持,AI PC算力与能效双突破
近日,英特尔Panther Lake架构正式揭开神秘面纱。作为首款基于Intel 18A制程工艺的客户端SoC,该处理器融合Lunar Lake高能效与Arrow Lake高性能优势,在CPU、GPU、NPU等核心部件实现全面升级,同时通过灵活模块化设计与先进无线技术,为AI PC规模化部署奠定基础。

制程工艺:18A技术突破,能效与密度双重飞跃
Panther Lake的核心竞争力始于Intel 18A制程工艺——这一英特尔自研的2nm级先进节点,首次将RibbonFET环绕栅极晶体管与PowerVia背面供电技术结合,解决了先进制程的电流控制与供电效率难题。
RibbonFET 晶体管采用“纳米丝带”式电流通道设计,栅极从四面环抱通道,漏电流减少的同时,开关速度提升15%,驱动电流增强20%,可在相同电压下提升芯片性能,或在相同性能下降低功耗。PowerVia技术则将供电电路转移至晶圆背面,使正面仅保留信号互连,不仅让晶体管密度提升10%,还减少了30%的从封装到晶体管的压降,为高频电路提供更稳定的电力支持。

相较于前代Intel 3工艺,Intel 18A实现了15%的每瓦性能提升与30%的芯片密度提升,且良率表现优于过去15年推出的任一制程节点。目前,该工艺已在英特尔亚利桑那州Fab 52晶圆厂启动生产,预计2025年第四季度实现大规模量产,2026年初搭载该处理器的终端产品将正式上市。
核心架构:混合核心+智能调度,性能与能效平衡
Panther Lake延续并升级了混合核心架构,提供8核、16核、16核12Xe三种配置,最高搭载 16 个CPU核心(4个性能核+8个能效核+4个低功耗能效核),通过差异化核心分工与智能调度,适配从日常办公到高性能计算的全场景需求。
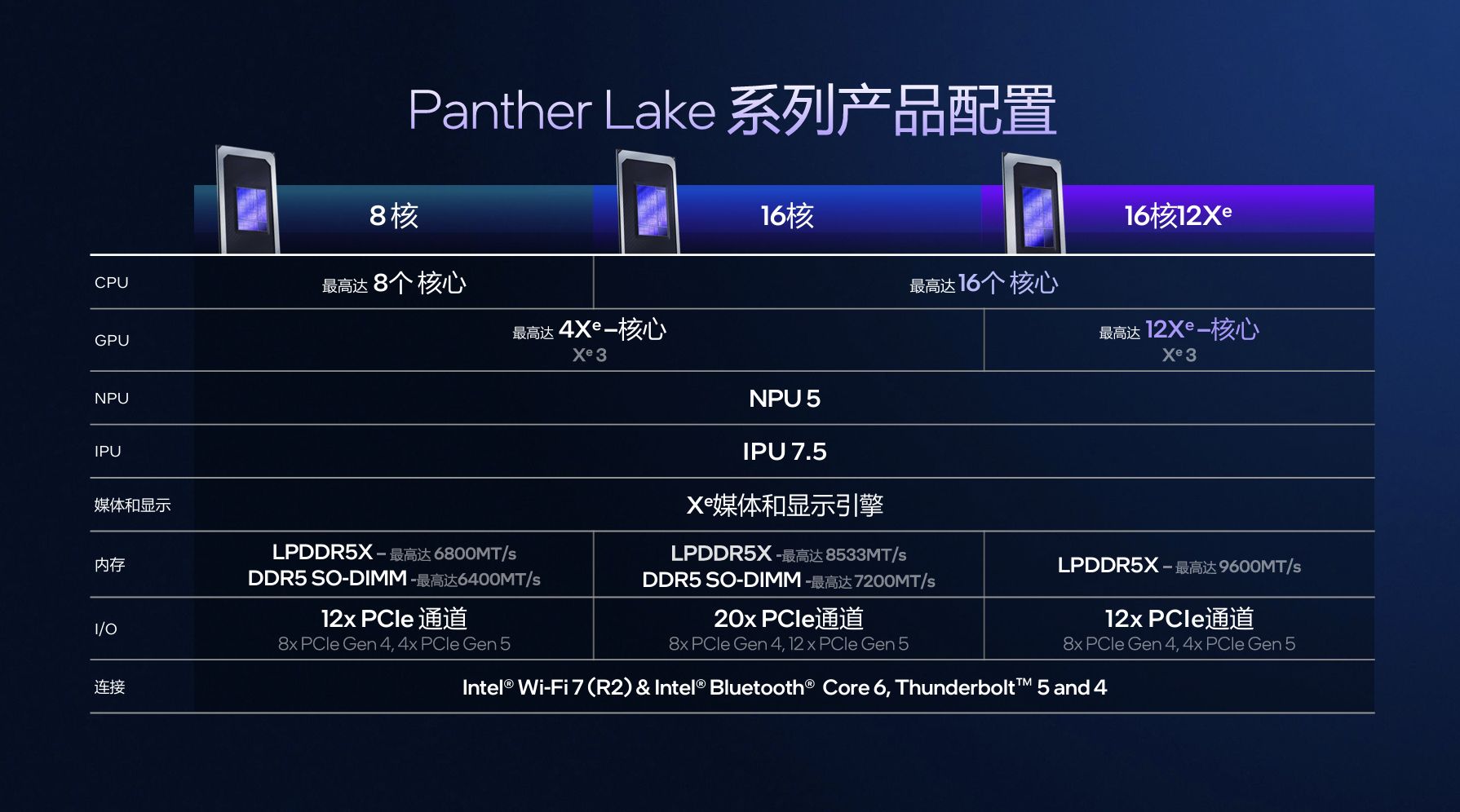
性能核采用全新Cougar Cove架构,基于Intel 18A制程优化,配备18个执行端口与最高18MB共享L3缓存,TLB容量提升1.5倍以适配现代复杂工作负载,同时升级内存消歧技术与分支预测算法——前者可打破内存读写指令的伪依赖,提升带宽利用率;后者通过算法优化与结构扩容,降低预测延迟并提高准确性,最终实现单线程性能较Lunar Lake、Arrow Lake H提升10%,相同性能下功耗降低40%。
能效核与低功耗能效核均采用Darkmont架构,其中能效核配备4MB共享L2缓存与26个调度端口,支持128B/周期L2缓存带宽,Nanocode性能与动态预取器控制能力升级,多线程处理效率显著提升;低功耗能效核则专注轻负载任务,L2缓存容量较Meteor Lake、Arrow Lake翻倍,可将后台任务(如微信通知、网盘同步)功耗压至0.5W。
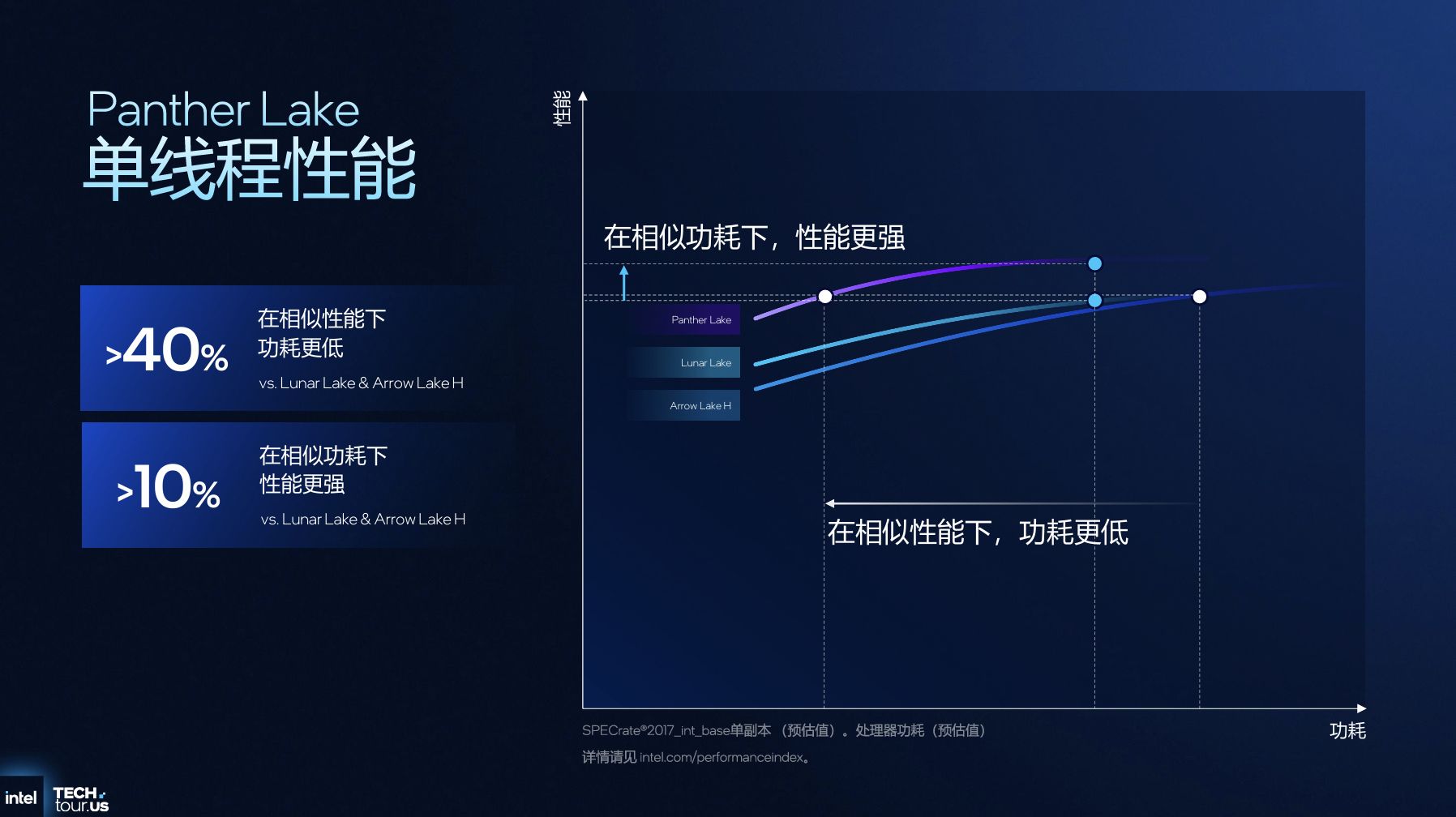
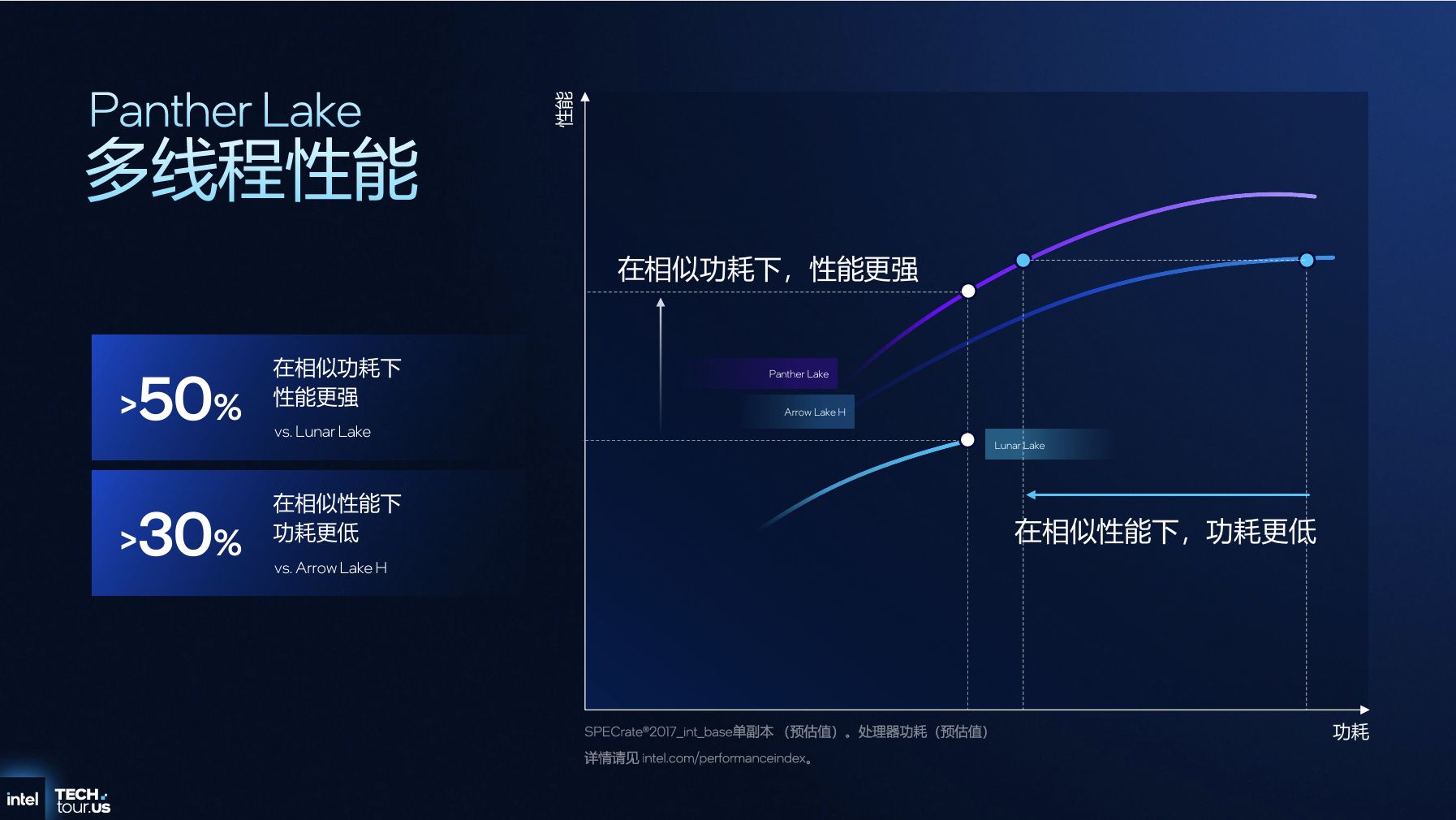
在调度机制上,Panther Lake升级硬件线程调度器,优化分类模型以匹配核心特性,扩大“繁忙”用例覆盖范围。调度逻辑遵循“轻负载优先LPE核→中负载迁移至E核→高负载调用P核”的层级策略,例如运行Teams视频会议时,负载集中在LPE核以降低功耗;执行Cinebench 2024多线程测试时,全核心协同释放性能,最终实现多核性能较Lunar Lake提升50%,相同性能下较Arrow Lake H功耗降低30%。
图形与AI:Xe3 GPU+NPU5,180TOPS算力支撑多场景需求
为满足AI PC的图形渲染与智能计算需求,Panther Lake在GPU与NPU上进行架构革新,平台总算力达到180TOPS,可覆盖游戏、创作、AI推理等多元场景。

GPU采用全新Xe3架构,提供4Xe与12Xe两种配置,最高搭载12个Xe核心、96个XMX引擎与12个光线追踪单元,L2缓存容量提升至16MB。其中,第三代Xe核心集成8个512位矢量引擎与8个2048位XMX引擎,线程数增加25%并支持FP8反量化,AI算力达120TOPS;光线追踪单元支持异步动态光线管理,可避免光线拥堵,搭配全新URB管理器,异向性过滤与模板测试速率均提升2倍。实测数据显示,Xe3 GPU图形性能较Lunar Lake提升50%,每瓦性能较 Arrow Lake H提升40%,运行《赛博朋克 2077》、《控制》等3A游戏时,帧率与画面流畅度显著优于前代。
同时,Xe3 GPU升级XeSS 3技术,新增多帧生成功能(XeSS-MFG)——通过分析前后帧的运动矢量与深度信息,可在原生渲染帧之间插入最多3帧中间帧,在《三角洲行动》等游戏中,可实现120帧高流畅度,且延迟仅增加3ms。

NPU方面,Panther Lake搭载第五代NPU5,通过优化芯片面积效率,在单位面积下实现40%的TOPS提升,总算力达50TOPS。其核心升级在于MAC阵列规模翻倍,支持INT8/FP8混合精度计算,4096MAC/周期的INT8与FP8运算能力,较FP16精度下的吞吐量提升1倍,且功耗降低50%。此外,NPU5集成3个神经计算引擎(NCE)、6个SHAVE DSP与4.5MB暂存器内存,可高效运行语音唤醒、实时翻译、图像降噪等AI任务,例如支持30B参数大语言模型,实时生成会议纪要仅需 1.2秒。
连接与影像:Wi-Fi 7+IPU7.5,体验全面升级
在无线连接与影像处理上,Panther Lake同样带来行业领先配置。

无线方面,该处理器集成英特尔Wi-Fi 7 R2(BE211 CRF 模块,代号 Killer 1775)与蓝牙Core 6.0,支持5GHz/6GHz双频段,信道带宽最高达320MHz,较Wi-Fi 6/6E翻倍;新增多链路重配置、限定TWT、单链路eMLSR等功能,可动态分配网络资源,降低延迟的同时节省功耗。蓝牙6.0则支持 LE 音频,功耗降低50%,并实现Auracast广播音频与10cm精度的 “查找我的设备” 功能,双蓝牙链路设计使通信距离提升至52米,稳定性显著增强。
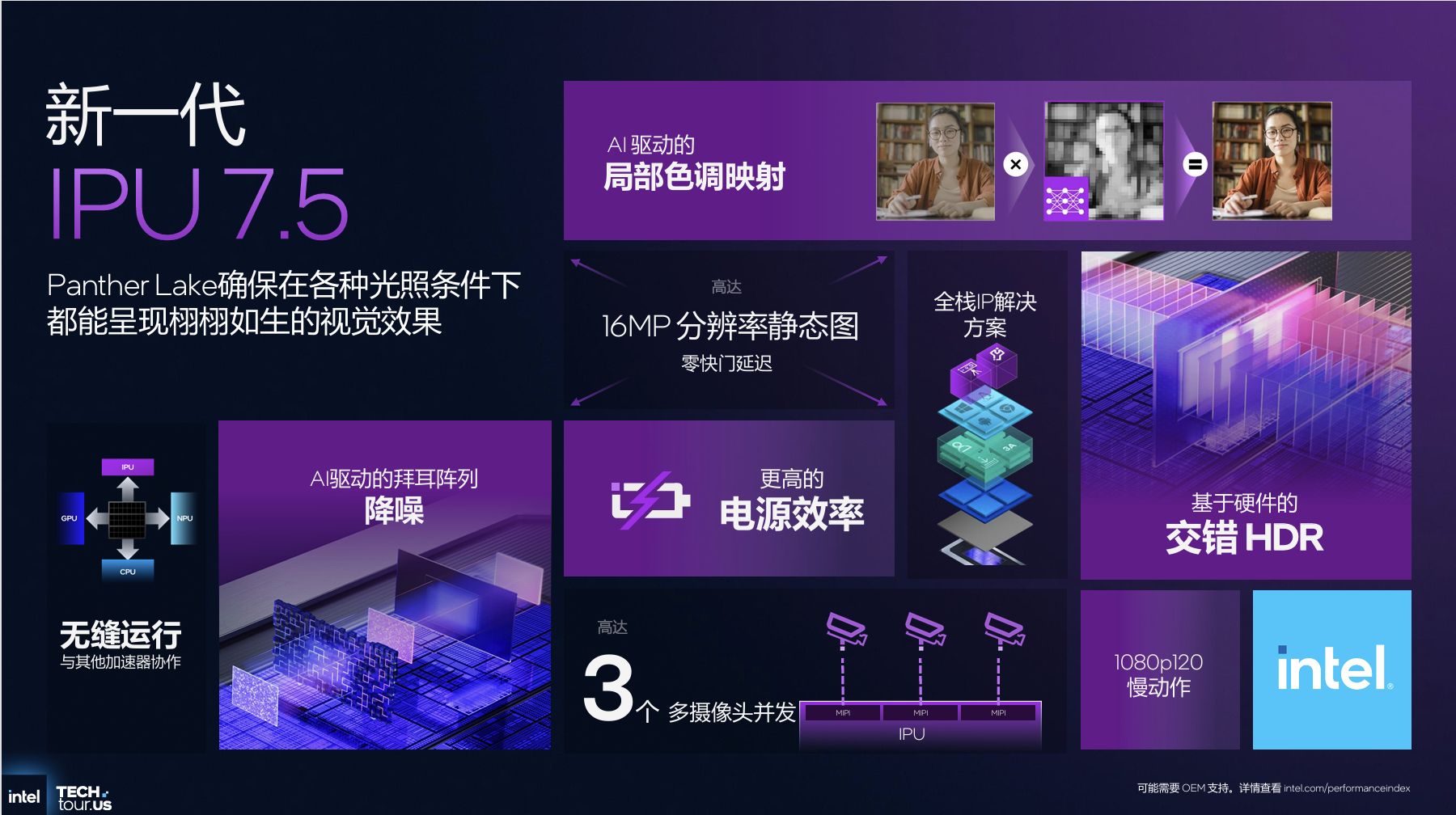
影像处理上,Panther Lake搭载新一代IPU7.5,通过硬件加速实现双重曝光交错HDR(sHDR),在4K分辨率下功耗降低1.5W;引入AI降噪与AI局部色调映射技术,弱光环境下图像清晰度提升,且无光晕与色彩伪影。同时,IPU7.5支持3路1080P摄像头并发与1080P120 帧慢动作录制,可满足高质量视频会议与内容创作需求。
市场意义:AI PC门槛降低,覆盖全价位段
Panther Lake通过模块化设计降低了AI PC的普及门槛——计算模块采用Intel 18A工艺保证核心性能,GPU与平台控制模块则灵活搭配不同制程,既控制成本,又为OEM厂商提供多样化选择。目前公布的三款配置中,8核4Xe版本适合入门级轻薄本,16核4Xe版本面向游戏本与生产力设备,16核12Xe旗舰版则瞄准高端创作本与AI工作站,未来3000元价位段的轻薄本也有望搭载该处理器,让AI功能惠及更多用户。

英特尔客户端计算事业部副总裁高嵩表示,Panther Lake的目标是“推动AI PC从概念走向规模化”,其不仅是一款处理器,更是一个整合硬件、软件与生态的平台。随着该处理器的量产与终端产品上市,AI PC将正式进入全场景普及阶段,为用户带来更智能、高效的计算体验。
本文由方向对了资讯网发布,不代表方向对了资讯网立场,转载联系作者并注明出处:https://www.zhenyes.com/digi/5784.html
