
全面开源!商汤日日新SenseNova U1发布,迈向模型理解生成统一时代
今天,商汤科技正式发布并开源
NEO-unify架构彻底摒弃了主流的拼接式,去除了视觉编码器(VE)和变分自编码器(VAE),重新构建了统一的表征空间,并且深入融入每一层计算中,从而实现从模态集成向原生统一的范式跨越。
SenseNova U1系列模型能够将语言与视觉信息作为统一的复合体直接建模,实现语言和视觉信息的高效协同,让理解与生成能力同步增强,在保留语义丰富度的同时,维持像素级的视觉保真度。
在逻辑推理与空间智能等方向上,它能够深度理解物理世界的复杂布局与精细关系;在未来,它还能为机器人提供具身大脑,实现在单一模型闭环内完成从复杂环境感知、逻辑推演到精准任务执行的全过程,为推动技术与产业发展提供重要基础与关键引擎。
本次开源发布的是 SenseNova U1 的轻量版系列 SenseNova U1 Lite。它包含两个不同规格的模型:
- SenseNova-U1-8B-MoT:基于稠密骨干网络
- SenseNova-U1-A3B-MoT:基于混合专家(MoE) 骨干网络
访问GitHub https://github.com/OpenSenseNova/SenseNova-U1 、Hugging Face https://huggingface.co/collections/sensenova/sensenova-u1了解更多信息。我们也将在近期公布详实的技术报告。
极致高效,以小搏大:开源 SOTA,比肩商用
效率,是统一模型架构的核心技术优势。
传统多模态模型是把视觉编码器和语言骨干通过适配器拼接在一起的。它像一个“说不同语言的人组成的工作组”:有人专门看图,把图像翻译为语言,有人专门理解文字,进行推理,有人把结果再翻译为设计指令,把图画出来。每完成一次任务,信息都要在不同成员之间来回传递。这个过程虽然可行,但难免会有等待、误解和信息损耗。为了弥补这些损耗,模型往往需要做得更大才能达到好的效果。
SenseNova U1 是基于统一表征空间构建的,更像是一个从一开始就同时掌握多项技能的人。它不是先看懂图像、再翻译成文字、再交给另一个系统理解,而是在同一套“思考方式”里直接处理图像、文字等不同信息。图像和语言不再是两套系统之间的接力,而是在同一个大脑中自然融合。这样带来的好处是:信息流转更快捷,理解更直接,生成更高效。模型不需要依赖单纯堆大参数来弥补中间转换的损耗,而是通过统一的内部表征,把不同模态的信息以更紧凑、更高密度的方式组织起来。
简单来说,传统架构像是“多人协作、层层转述”;SenseNova U1 更像是“一个全能大脑,直接理解,直接表达”。少了中间转译,信息损耗更低,也能在相对更精简的模型规模下,实现更强的多模态理解与生成能力。
实验结果验证了我们的想法。在涵盖图像理解、图像生成与编辑、空间智能和视觉推理的多项基准测试中,SenseNova U1 Lite均达到同量级开源模型SOTA水平,为统一多模态理解与生成树立了新的标杆。甚至仅凭8B-MoT的较小规格,就能达到甚至超越部分大型商业闭源模型,展现出全维度多领域的统治力。
图像理解基准测试结果 | 图像生成基准测试结果 | 视觉推理基准测试结果 |



以下两组对比图更直观地展现了 SenseNova U1 Lite 在效率上的突出优势。在通用的图像生成测试中,SenseNova U1 Lite不但在图像生成质量上比肩 Qwen-Image 2.0 Pro或 Seedream 4.5 等大型闭源模型,达到商业级水准,还在推理响应速度上有显著优势。即使在极具挑战性、开源模型一直做不好的复杂信息图生成任务中,SenseNova U1 Lite 也表现出商业级的水准,对复杂信息图的排版和文字有很强的控制力。
Generation Latency vs. Averaging Performance on OneIG (EN, ZH), LongText (EN, ZH), BizGenEval (Easy, Hard), CVTG and IGenBench | Generation Latency vs. Averaging Performance on Infographic Benchmarks, i.e., BizGenEval (Easy, Hard), and IGenBench |


以下实际例子,展现了 SenseNova U1 Lite的商业级复杂信息图生成能力。









我们正在沿着当前的技术路径继续 Scale,计划在未来推出体量更大的模型。我们相信,基于高效的原生架构,可以以低得多的计算成本达到国际顶尖模型的水平。
业内首创:连续性图文创作输出
凭借NEO-Unify架构的优势,SenseNova U1在业内首个实现连续性的图文创作输出。并且只需要单次单模型调用,就能输出更高质量的作品,相比传统范式,实现了效率的大幅提升。
SenseNova U1 所具备的原生图文理解生成能力,能天然将图像和文本底层融合信号完整的保留上下文中,区别于过去只能利用多模型串联勉强实现,它的图像间风格具备明显的高一致性,能在统一表征空间进行高效连贯思考。
下面两个案例中,SenseNova U1 通过连贯高保真度的图文交错思考输出。
任务一:五分熟牛排做法:SenseNova U1 可以通过思考和规划产生分步的过程,并且给每一步输出对应的图像展示。各个步骤的图示表现出极高的一致性。

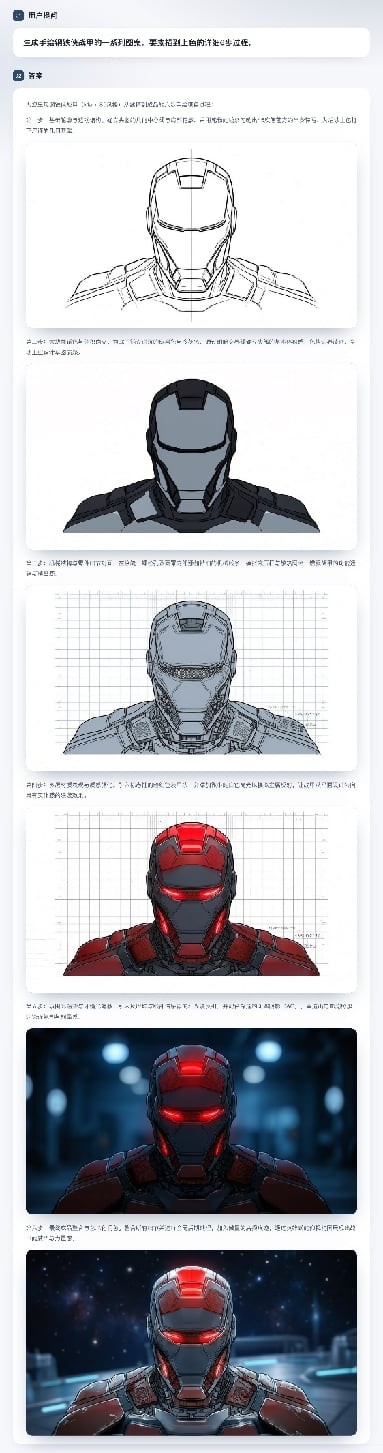
任务二:绘制一个钢铁侠图案:它可以从扫描草稿出发,逐步进行连续创作,最终做出一个完成度很高的图像。每一步创作的过程对于前一步的结构和细节都做了精准的保持 —— 一个统一表征的共享上下文在其中发挥了关键作用。
全网开源,即刻可用
开源部署
- GitHub:https://github.com/OpenSenseNova/SenseNova-U1
- Hugging Face:https://huggingface.co/collections/sensenova/sensenova-u1
- 欢迎调用 SenseNova U1 Skill https://github.com/OpenSenseNova/SenseNova-Skills ,浏览海量样例库,获取Prompt编写指南,化繁为简(繁杂文->有趣图),让您的Agent成为信息图生成高手
在线体验
- 即将上线办公小浣熊
我们相信,原生统一的多模态智能是通往 AGI 的必经之路。未来,我们还将持续推动开源生态建设,并发布更大参数规模的 U1 系列模型。迎社区广大用户和开发者提出宝贵建议,共同定义智能交互的未来。
*NEO-unify技术博客:https://www.sensetime.com/cn/news-detail/51170548?categoryId=73
SenseNova U1 Lite专属群,欢迎入群扫码交流~↓↓↓

+++
关于商汤
作为人工智能软件公司,商汤科技以“坚持原创,让AI引领人类进步”为使命,旨在持续引领人工智能前沿研究,持续打造更具拓展性更普惠的人工智能软件平台,推动经济、社会和人类的发展,并持续吸引及培养顶尖人才,共同塑造未来。
商汤科技拥有深厚的学术积累,并长期投入于原创技术研究,不断增强行业领先的多模态、多任务通用人工智能能力,涵盖感知智能、自然语言处理、决策智能、智能内容生成等关键技术领域,同时包含AI芯片、AI传感器及AI算力基础设施在内的关键能力。
商汤科技业务涵盖生成式AI、视觉AI和创新业务,以高效率、低成本、规模化的AI创新和落地,打通商业价值闭环,引领人工智能进入工业化发展阶段。商汤前瞻性打造新型人工智能基础设施——商汤AI大装置SenseCore,打通算力、算法和平台,并在此基础上建立“商汤日日新SenseNova”大模型及研发体系,以低成本解锁通用人工智能任务的能力。此外,商汤科技持续领跑计算机视觉市场,商汤方舟 SenseFoundry以多年积累计算机视觉能力,辅以前沿多模态大模型,为国内外各行业提供更加稳定高效的视觉Al支撑。
商汤倡导“发展”的人工智能伦理观,并积极参与有关数据安全、隐私保护、人工智能伦理道德和可持续人工智能的行业、国家及国际标准的制订,与多个国内及多边机构就人工智能的可持续及伦理发展开展了密切合作。商汤《AI可持续发展道德准则》被联合国人工智能战略资源指南选录,并于2021年6月发表,是亚洲唯一获此殊荣的人工智能公司。
目前,商汤科技已于香港交易所主板挂牌上市。商汤在香港、上海、北京、深圳、成都、杭州、西安、新加坡、曼谷、吉隆坡、利雅得、阿布扎比、迪拜、首尔等地设立办公室。另外,商汤科技在德国、泰国、印度尼西亚、菲律宾等国家均有业务。更多信息,请访问商汤科技网站、微信、微博和领英。
本文由方向对了资讯网发布,不代表方向对了资讯网立场,转载联系作者并注明出处:https://www.zhenyes.com/industry/7557.html

